IFSolver 的原理解析
IFSolver 是一个用以自动匹配和解算 IFS @ 2020 的程序,使用 Python 和 OpenCV 库编写。
前言
自从疫情爆发后,Ingress First Saturday(IFS)也搬到了线上。除了要求直播唠嗑外,为了不让众参与者们闲着,IFS-UN 也费尽心思地提高了 Passcode 解谜的难度。理论而言它确实能带动广大 Agent 的积极性,但是由于大家都是鸽子,事实上任务都由 POC 来承担,为了保证 POC 们有足够事件摸鱼,需要一个高效和方便的工具来辅助解算 Passcode。
随后我在 7 月的 IFS 上折腾了一下午,最终实现了这个程序的第一版,然后在 8 月的 IFS 中,此程序进一步获得了改进。
输入描述
IFS 的谜题图片是一个jpg(有时候是png)的彩色图片,其中包含了若干行列 Portal 的图像矩阵。

我们将这个图像矩阵记为 $I$,对于第 $i$ 行 $j$ 列的图像记为 $I_{i,j}$
输出描述
通过对这些图片进行识别,找出对应的 Portal 按照经纬度和先后顺序形成的图像,共 $j$ 个,记为 $G_j$ 。
计算流程
- 首先从图像中提取所有 $I_{i,j}$。
- 然后,通过匹配,查找到对于每一个图像 $I_{i,j}$ 相对应的相似度最高的 Portal,记为 $M(I_{i,j})=P_{i,j}$。
- 将这些 Portal 按列连接生成经纬度图像,记为 $Geo(P_{1,j}, P_{2,j}…P_{n,j})=G_j$
- 将这些生成的图像拼接成为完整的 Passcode 图像 $G$,即为我们需要的结果。
存在的问题
- 需要查找大量的数据,某些状况下,半径 1 公里(IFS 的要求)内会存在的大于 1500 个 Portal,需要匹配的图像有约 100 个。
- IFS 提供的 jpg 图像边界不清晰,难以划分边界。
- 由于涉及到后续的地理位置操作,任何 False Positive / True Negative 判断均会导致生成的 Passcode 图像难以识别。
- 部分 Portal 图像过于接近(例如石狮子)。
步骤一:导出并下载 Portal 数据
这一步 IITC 有下载 Portal 信息的插件,它能够把 Portal 的名称、经纬度,以及更重要的 - 图片 url 下载下来,它将会导出成一个 csv 格式的文档。
(注意插件默认导出的是以 utf-8 编码后的文本,如果需要导出可读的 Portal 匹配结果,需要将其转换为中文)。
(还需注意的是某些 Portal 图片缺失,需要予以排除)。
1 | |
如果使用单线程的下载,这上千张图片会下载很久。因此,使用 python 内建的多线程支持,我们能够快速地下载完全部的图片数据(实际使用状况下,一般选择9-12线程下载)。
1 | |
步骤二:预提取特征
为了降低拿到谜题后的工作量,让大伙们更快地拿到 passcode,我们并不一定需要在拿到图后,才开始进行全部的流程,对于提取图像特征这一任务而言,完全可以在此之前就完成。
至于用何种方式进行提取,这就与以何种方式进行匹配相关了。
我这里使用了经典的 Python OpenCV 库作为主要工具。有以下几种检测特征的方式:
Harris:是一个利用角点进行检测的算法。不会采用,因为其对尺度变化敏感,而我们需要匹配的图片尺度显然是经过了缩放,其中夹杂着 JPG 图片压缩和图像分割误差导致的变化。
SIFT (尺度不变性特征变换) 是利用 DoG 金字塔检测极值点并提取特征 descriptor 的方法,对旋转、尺度缩放、亮度变化也具有不变性。
ORB (Oriented FAST and Rotated BRIEF) 事实上是两种检测法的融合。它具有超级高效(百倍于 SIFT)的特点,通过 FAST 检测特征点,再通过 BRIEF 检测特征 descriptor。
SIFT 算法比较准确,甚至可以考虑在原图上不做分割,直接与数千张图片进行识别。但不巧的是,这是一个具有专利的算法 (今年 3 月到期啦!),在 OpenCV 上还暂未从 Non-free 挪出来 (Soon™)。
同时,考虑到开发和 debug 上的难度和数据量级,需要随时检验匹配结果,我在这里采用了 ORB 方法来提取特征。
1 | |
其中 kp 和 des 分别是提取出的特征点和对应的 descriptor。
这些特征将会以 pickle 的方式保存至硬盘上,以供后续读取。
图中即为某个 Portal 图片提取到的特征点可视化预览。

这里假设从第 $k$ 个图像中提取出的第 $l$ 个特征点为 $K_{k, l}$,则对于每个分割图像 $I_{i,j}$ 需要实现
$$M(I_{i,j}) = \mathop{\arg \max}(k)(\sum_{l} Match(I_{i,j}, K_{k, l}))$$
即最大化匹配的特征点数量,将具备此特征的图像作为匹配的结果。
步骤三:图像的分割
为了提高识别的准确性,需要将一整个图像 $I$ (见上) 分割成 $I_{ij}$,这个过程尤为关键,若未完全提取所有的图像,或出现了额外的匹配图像,都将会大幅度影响到后续的匹配和作图结果。
一种解决方法是较为简单的类似 Photoshop 的方法,通过选取背景色(目前来看是灰色),进行扩展,再将剩下的区域依次分割成不同的小块。
但这种方法受到背景颜色的影响(经过 JPG 压缩的图片背景可见明显的噪声,且方差很大,容易与相似颜色的 Portal 图片相混淆),因此,改用了基于梯度的分割方法。
后来发现这个可以使用 FloodFill 解决。
首先,由于分割图片的背景颜色是深灰色,我们需要将其替换成在灰度模式下更易区分的颜色。
回想一下,如果使用 GIMP/Photoshop,我们会怎么做呢?
首先会使用「魔棒」工具选择一部分选区,然后「扩展选区」,再通过「油漆桶」填充。
那么如何在 OpenCV 上方便地一步完成呢?
这时候就需要用到 FloodFill,一个运用洪水扩张原理的连通区域提取算法,只需要设定好阈值,就能够在较低损失的程度下,提取出图像中的背景区域,并将其置为白色(较容易分辨),我们可以以左上角的点为基准。
1 | |
然后,图片需要被转换为灰度。
1 | |
本程序使用 OpenCV 的形态学运算用于检测边缘 / 梯度。创建一个指定大小的 kernel $K$。
1 | |
将图片使用“膨胀”和“腐蚀”,得到其形态学梯度,即 $S_D(I) = I \oplus K - I \ominus K$。
1 | |
根据获取到的梯度和阈值,将结果二值化,为了可以手动修正,这里的 thres 是一个变量:
1 | |
然后根据上面获得的内容,进行轮廓查找,并获取嵌套的轮廓树的根节点。
1 | |
然而,由于图像信息比较复杂,获取到的轮廓可能只是图像的一部分,这时候就需要判断这些轮廓的大小,如果小于图像应有的大小,就忽略它。
1 | |
通过以上流程分割出的图像效果如下:

可以从中发现,有些图像识别不完整,但完全不用担心,只要覆盖到了图像的大部分区域,就能匹配成功。
步骤四:图像的匹配
接下来,就是将提取出的这些图片与上千张已经提取好特征的 Portal 图片进行匹配了,由于考虑到 Portal 图像的相似性,并且受到 ORB 方案的 Descriptor 数据类型限制,我们采用了能够获得最优方案的 BFMatcher 暴力匹配方案,然后从待匹配图像中提取特征。
1 | |
然后运行匹配,获得匹配的特征点列表。
1 | |
通过对匹配出的特征点与总数的占比,可以得出一个置信度,并使用阈值判断每次匹配是否成功,以下是匹配的效果(Portal 的经纬度已经标注在上面)。

步骤五:依照坐标画图
在画图前,需要先知道这些图片所在的行列(先前匹配时只能获取到这些图片左上角的 x 和 y)。稳妥一点的方法可以利用类似 K-Means 的聚类方式对 x 坐标进行归类,然后按照 y 坐标的大小排序。但这里直接使用了简单粗暴的 x/200 方案。
对于每组数据 $P_{i,:}$,建立一个 640 x 640 大小的画布,其经纬度在画布上的映射关系为:
$$ G_{i,j} = P_{i,j} / range(P_{i,:}) \cdot (640 - 2 L_{margin}) + L_{margin} $$
然后根据置信度进行标注,最后将这些 Portal 连接,拼接成长图,就是 Passcode 了!
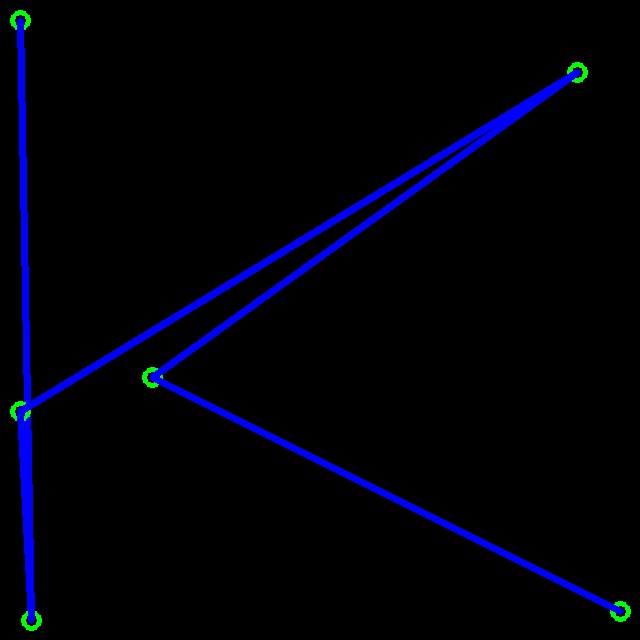
效果如图。
后续还可以通过各种操作进行数字的识别(参考 MNIST),但由于猩猩的脑洞实在很大,可能并不能完美识别这些字符。